Mini-Omni: A Revolutionary Leap in Real-Time Conversational AI
Researchers Zhifei Xie and Changqiao Wu recently introduced Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming, a groundbreaking innovation in the field of conversational AI. This model pushes the boundaries of real-time multimodal interactions, incorporating both speech and text to create seamless, natural conversations with minimal latency.
Key Advancements in Mini-Omni
- End-to-End Speech Interaction: Unlike traditional models, which rely on separate Text-to-Speech (TTS) systems for voice output, Mini-Omni integrates both input and output processing within a single framework. This end-to-end approach eliminates the need for auxiliary systems, significantly reducing latency and enhancing the fluidity of conversations(ar5iv).
- Simultaneous Processing: Mini-Omni introduces the ability to “hear, talk, and think” concurrently. By employing a parallel text-audio generation system, the model can process incoming audio and generate responses simultaneously. This innovation ensures smoother, more immediate conversational flows and eliminates the stop-start interaction style common in older systems(Neurohive).
- Batch-Parallel Inference: One of the standout innovations is Mini-Omni’s batch-parallel inference strategy, which allows for multiple processes to run in parallel, thereby speeding up response times and enabling true real-time interaction(Indika AI).
- “Any Model Can Talk” Framework: Mini-Omni also serves as a flexible platform that can be adapted to existing language models like LLaMA and Vicuna with minimal retraining. This is made possible through the “Any Model Can Talk” framework, which extends these models’ speech capabilities using techniques like modality alignment and multimodal fine-tuning (Papers with Code).
- Real-Time Reasoning with Audio: Perhaps one of the most novel aspects of Mini-Omni is its ability to perform reasoning directly within the audio space. This eliminates the intermediate step of converting audio to text for reasoning, thereby retaining the nuances of spoken language and reducing the time required for processing(Indika AI).
Technical Foundation and Performance
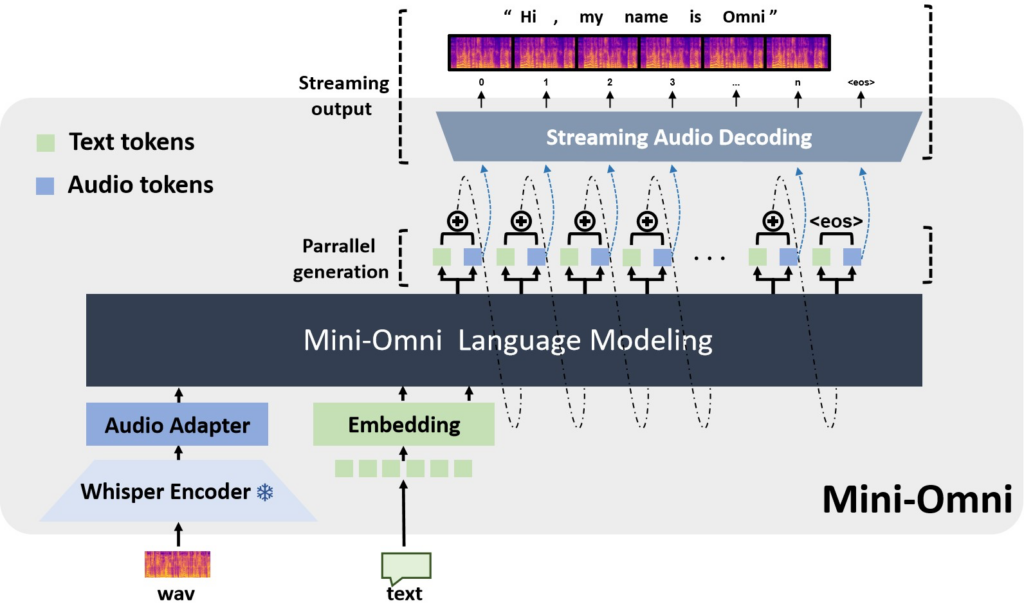
The architecture behind Mini-Omni builds on the Qwen2-0.5B transformer and integrates a Whisper-small encoderfor speech processing. The model was trained using 8,000 hours of speech data and 2 million text samples from the Open-Orca dataset, along with a specially curated VoiceAssistant-400K dataset, optimized for real-time conversational tasks(ar5iv)(Neurohive).
In terms of performance, Mini-Omni achieved an impressive word error rate (WER) of 4.5% on the LibriSpeech test-clean dataset, closely rivaling leading models like Whisper-small, which reached 3.4%(Neurohive).
Applications and Future Directions
Mini-Omni opens up exciting possibilities across several domains:
- Customer Support: With its high-speed response capabilities, Mini-Omni can transform customer service environments, offering instant, human-like interactions.
- Virtual Assistants: The model’s ability to handle continuous audio input and output makes it a prime candidate for next-generation virtual assistants.
- Assistive Technologies: Mini-Omni’s real-time processing can improve accessibility tools, aiding individuals with speech or hearing impairments(Indika AI).
Challenges and Ethical Considerations
While Mini-Omni represents a major leap forward, it also faces several challenges. Scalability and resource management will be critical as the model expands for widespread use. Additionally, ethical concerns regarding data privacy and bias in training data will need to be addressed as conversational AI systems become increasingly integrated into everyday life(Indika AI).
In-Depth Analysis: Unpacking the Potential and Limitations of Mini-Omni in Conversational AI
In the realm of conversational AI, Mini-Omni stands out as a highly innovative model, pushing the boundaries of real-time interaction between humans and machines. After reviewing the foundational capabilities of the model in our initial report, this follow-up analysis delves deeper into its architecture, potential applications, and the critical challenges that need to be addressed to ensure scalability, ethical deployment, and broader industry adoption.
Architecture and Design: Beyond Parallel Processing
The architecture of Mini-Omni integrates speech recognition, real-time reasoning, and speech generation in a highly efficient manner. At the core of the model is a transformer-based Qwen2-0.5B architecture with Whisper-small encoders that enable robust processing of audio inputs(Neurohive). This combination sets Mini-Omni apart from traditional models, which generally rely on text processing and separate modules for audio input/output, often leading to delays.
However, one of the most compelling aspects of the architecture is its batch-parallel inference strategy. This strategy allows Mini-Omni to perform multiple operations concurrently—effectively listening, thinking, and responding at the same time(Indika AI). This feature makes the model highly responsive, making it well-suited for applications that require rapid, seamless conversation, such as virtual assistants, customer service bots, and even real-time translation services.
Yet, with this advancement comes complexity. While parallel processing greatly reduces latency, it also increases the computational load. For widespread deployment, particularly in consumer-grade hardware or cloud-based solutions, resource optimization becomes crucial. Future iterations may need to explore ways to further optimize the model to handle heavy workloads without significantly increasing operational costs.
Real-Time Reasoning in Audio: A Major Leap or a Narrow Use Case?
Mini-Omni’s ability to reason within the audio space is perhaps its most groundbreaking feature(Indika AI). Traditional conversational systems typically convert speech to text before applying reasoning algorithms. This process, while effective in some domains, can result in lost contextual information, particularly the nuances in speech such as tone, pauses, or emphasis.
Mini-Omni bypasses this by reasoning directly on audio data, preserving these subtleties and enabling richer, more context-aware interactions. However, this approach raises some interesting questions:
- How well does the model perform across different languages and dialects? Speech is inherently complex, with variations in pronunciation, intonation, and regional accents. While the VoiceAssistant-400K dataset has been instrumental in fine-tuning Mini-Omni, scaling to multilingual environments or non-standard accents could present hurdles. Performance across a broader spectrum of linguistic styles remains to be rigorously tested.
- Can Mini-Omni adapt to emotional cues? Human conversations are not just about words but also about the emotions behind them. While reasoning in audio provides an edge, further development is needed to ensure the model can detect emotional states and adjust its responses accordingly. This presents a new frontier in emotional intelligence for AI models, where Mini-Omni might play a crucial role.
“Any Model Can Talk” Framework: Democratizing Speech AI?
One of the most exciting prospects of Mini-Omni is its “Any Model Can Talk” framework, which enables other language models like LLaMA, Vicuna, and Baichuan to adopt speech capabilities without the need for extensive retraining. This modular approach democratizes access to speech-based interaction, allowing a wider range of AI systems to integrate voice functionalities.
This flexibility is a significant leap for researchers and developers working with models that traditionally focus on text. By adding voice interaction capabilities to models that were not initially designed for such tasks, Mini-Omni is poised to become an essential tool in fields like AI research, healthcare, and education, where real-time voice interaction is increasingly critical.
Performance in Real-World Scenarios: The Pros and Cons
When it comes to performance, Mini-Omni demonstrated strong results, particularly in automatic speech recognition (ASR). The model achieved a word error rate (WER) of 4.5% on the LibriSpeech test-clean dataset, a metric that puts it in close competition with more established models like Whisper-small(
Neurohive)(
However, real-world environments are often far messier than clean datasets like LibriSpeech. Factors like background noise, cross-talk, and non-standard speech patterns can degrade performance. While Mini-Omni has shown promise, additional testing in these more chaotic settings is necessary to understand how well it can perform outside controlled environments. Speech recognition models generally face challenges with noisy data, and it remains to be seen how robust Mini-Omni can be in high-noise conditions, such as crowded call centers or outdoor environments.
Ethical and Privacy Considerations
As Mini-Omni advances toward commercial applications, the question of ethical AI deployment becomes increasingly pertinent. Real-time conversational models raise concerns about privacy, particularly in sensitive environments like healthcare, finance, and personal assistance. The collection and processing of audio data necessitate stringent data protection protocols. How Mini-Omni handles data retention, anonymization, and real-time deletion will be critical to its broader adoption(
Additionally, bias in training data is a significant challenge. Many speech models have been criticized for performing poorly across different demographic groups due to biased training datasets. As Mini-Omni expands, ensuring that its training data is diverse and inclusive will be essential to prevent biases that disproportionately affect certain groups. Researchers will need to carefully monitor and mitigate any biases that emerge during deployment to ensure equitable AI systems.
Conclusion: Potential and Path Forward
In summary, Mini-Omni represents a significant leap forward in the development of real-time, multimodal conversational AI. Its architecture, combining parallel processing and real-time reasoning in audio, opens the door to a new generation of applications, from smarter virtual assistants to more responsive customer service bots. The “Any Model Can Talk” framework further enhances its utility, enabling a broad range of AI models to adopt speech capabilities with minimal training.
However, as with any new technology, challenges remain. Resource optimization, performance in noisy environments, and ethical concerns will need to be addressed for Mini-Omni to achieve its full potential. As the AI community continues to innovate, Mini-Omni offers an exciting glimpse into the future of human-computer interaction.
As this technology continues to evolve, researchers and developers will need to work together to ensure that these models can scale effectively, are deployed ethically, and meet the complex needs of real-world applications.
For more technical details and code access, visit the official Mini-Omni GitHub repository and arXiv paper